The organizational secrets of the Large Hadron Collider
Solving complex problems at scale requires plenty of leadership and management. What it doesn't require is a top-down structure.


Solving complex problems at scale requires plenty of leadership and management. What it doesn't require is a top-down structure.
In early July 2022, the Large Hadron Collider (LHC), operated by the European Organization for Nuclear Research (CERN), was rebooted after a three-year pause. The new upgrades will help smash together more protons at higher energy levels, which will hopefully uncover new subatomic particles and increase our understanding of how the universe works. About a decade ago, LHC scientists discovered the Higgs boson, a particle that gives all matter its mass.
The effects of LHC's particle collisions are picked up and analyzed by four detectors--ATLAS, ALICE, CMS, LHCb--deployed around a 27-kilometer loop, 100 meters below ground near the Swiss Alps.
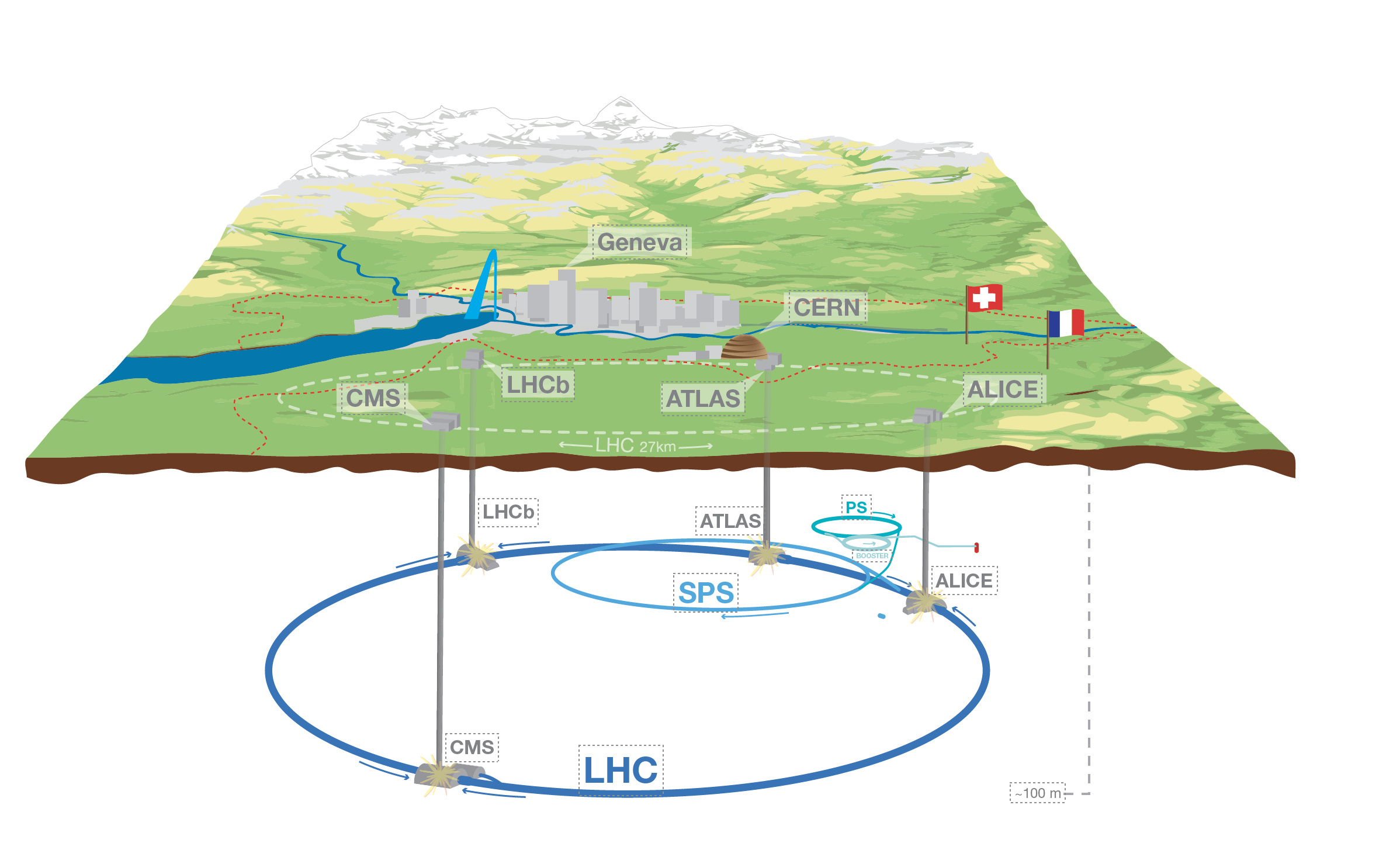
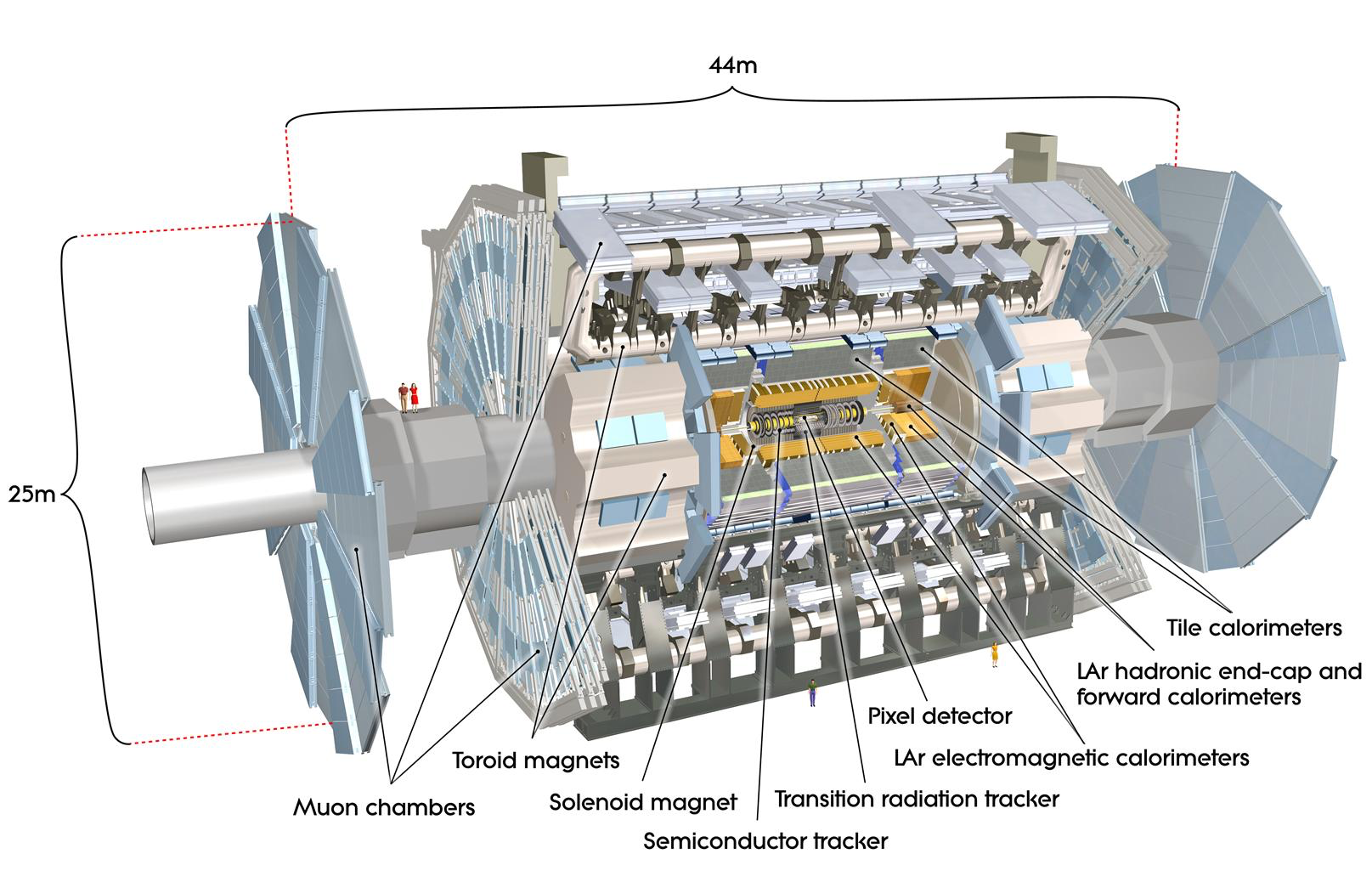
These detectors are among the most complex machines to have been developed by humans--they're 45 meters long, 25 meters high, and pack in than 10 million parts. Designing, building, and operating these detectors requires coordinating the work of thousands of people around the world, all seeking solve problems at the bleeding edge of science, technlogy, and engineering. You'd think that doing this is impossible without a top-down power structure. After all, unity of command ensures unity of purpose. Clear lines of authority minimize ambiguity. Tiered decision rights correlate power and competence. Absent formal hierarchy, there is anarchy, right? Well, maybe not.
Consider the ATLAS detector project, which involves more than 3,000 scientists from 180 institutions. In the early stages of the project, the ATLAS consortium struggled to find the right organizational design. Inevitably, the detector’s development and build-out would have to be broken into pieces. On other hand, all the subsystems, and there were hundreds of them, had to be seamlessly fused together. Therein lay the dilemma. While small teams cope well with uncertainty, huddling and pivoting as necessary, they can’t accommodate high levels of complexity. Conversely, large organizations are good at integrating diverse inputs, but only when the tasks are sequential and predictable. Working at the outer limits of science, and needing to encompass a vast expanse of technical knowledge, the ATLAS team faced high levels of uncertainty and complexity.
The default choice was centralization, but the downsides were substantial. The design and installation of the detector would require thousands of trade-offs—far more than could be handled by a centralized structure where issues get escalated for resolution. Moreover, no small steering group would have the breadth of knowledge required to make such trade-offs. Additionally, top-down decisions would provoke resistance from the consortium’s fiercely independent scientists.
In the end, the consortium opted for a bottom-up structure that relied on peer-to-peer coordination rather than a cadre of senior managers. Every sub-system had its own board, which included all the scientists working on that aspect of the project. The deliberations within these boards were open and collegial, but could also be heated. Occasionally, opposing teams would debate an issue in front of their colleagues who would then vote for what they believed was the best option.
As cross-system issues arose, temporary working groups were convened to hammer out solutions. When, for example the design of the primary detecting magnet turned out to require more space than originally envisioned, thus shrinking the room for other equipment, a task force was mustered and soon invented a work around. Throughout the project, subsystem boards published real time information on progress and challenges, and relevant experts were encouraged to comment online.
At the strategic level, major decisions about project priorities and technology choices were handled by the Collaboration Board. Every participating institution had a seat on the Board, and a two-thirds majority was required to greenlight a decision. Despite its scale and complexity, the ATLAS detector was completed on time and within budget.[1]
Bringing the ATLAS detector to life required tons of leadership and plenty of management. What it didn’t require was a pyramid of lines and boxes. No one within the ATLAS consortium had the power to hand down an order. Everyone was a colleague; no one was a boss. And yet, somehow, a disparate collection of scientists and engineers scattered across the globe managed to build a device that could accelerate particles to near light speed, crash them together, and measure the results.
The members of the ATLAS consortium had good reasons to challenge the value of a top-down power structure, and so do you.
For a detailed account of ATLAS' organizational model, see Max Boisot et al., eds., Collisions and Collaboration: The Organization of Learning in the ATLAS Experiment at the LHC (Oxford, UK: Oxford University Press, 2011). ↩︎